





DataOps
En DataOps-løsning hjælper dig med at udnytte dine industrielle data bedre.
Vores DataOps løsning
Med en DataOps-løsning udnyttes industrielle data bedre. DataOps fokuserer på at øge mængden og kvaliteten af dataleverancer, samtidig med at cyklustiden reduceres.
Øget fokus på industri 4.0 og digitalisering vil dramatisk øge mængden af data i industriel produktion i løbet af de næste par år. Mange mennesker vil bruge disse data i analyseværktøjer, lokalt eller i skyen, til at optimere processer og produktion.
En af de største udfordringer i dag er, at data fra maskiner og udstyr er inkonsekvente og ofte mangler struktur. Data relateret til f.eks. En maskine kan indeholde tags / signaler fra kontrolsystemet, men kan mangle “metadata” såsom placering, type og serienummer. Data fra andre maskiner kan have en anden navngivning eller enhed på signalerne. Dette skaber udfordringer, når data skal analyseres. For at få den fulde værdi af analysen skal data kunne analyseres på tværs af fabrikker, maskiner, processer og produkter.
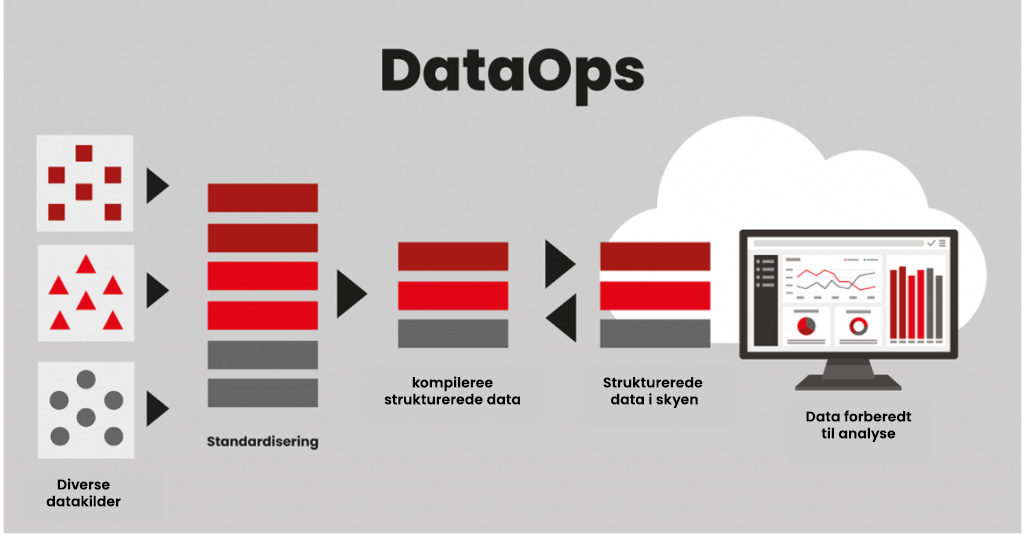
DataOps kommer fra ordet «Data Operations». Dette er en ny tilgang, der gør OT-data fra maskiner og udstyr lettere tilgængelige og i en form, der gør det lettere og tidsbesparende for datavidenskabsfolk, analytikere, ingeniører og it-personale at analysere data.
Hvordan fungerer DataOps?
Med DataOps kan data fra flere kilder (OPC, MQTT, SQL etc.) eller systemer kompileres, kontekstualiseres, struktureres og forberedes lokalt (på kanten), af OT-personale, der kender udstyret, inden de sendes til analyse og videre brug. Resultater fra analyser skal ligeledes kunne sendes tilbage til brug for optimering. Derfor skal datastrømmen også kunne styres og kontrolleres.

Problemfri kommunikation
I stedet for traditionelle en-til-en-integrationer kan en DataOps-løsning let skaleres. Dette gør det muligt at håndtere hundredvis af maskiner med titusinder af datapunkter via et sæt standardmodeller (f.eks. Motor, pumper osv.). Data udarbejdes og struktureres, før de videresendes, og det undgås at sende redundante data gennem systemet. Data Forskere, analytikere, ingeniører og it -personale modtager data, der ikke kræver yderligere behandling og modellering (kodning). Dette er meget tidsbesparende.
Bedre adgang for OT-personale
Industrielle enheder og it -systemer kommunikerer på forskellige måder. En DataOps -løsning skal kunne integreres problemfrit med industrielle enheder og datakilder, samtidig med at den giver værdi til it -applikationer. DataOps lægger vægt på kommunikation og samarbejde mellem Data Scientists, analytikere, ingeniører og IT- og OT -personale. Kontinuerlig og pålidelig adgang til data fra hele virksomheden vil effektivisere og sikre kvaliteten af analysearbejdet.


Dataanalyse af højere kvalitet
Industriel data bruges kun sekunder efter, at de er oprettet. Det betyder, at data skal kontekstualiseres i nærheden af maskinerne, og før de gemmes. En DataOps -løsning kører derfor tæt på enheden, samtidig med at den deler modeller på tværs af faciliteter og virksomheder for at standardisere og normalisere data. Kontrol af denne informationsstrøm er en vigtig komponent i en DataOps -løsning. OT -personale, der betjener maskinerne, vil kunne kontrollere datastrømmen og identificere ændringer i maskiner og udstyr. Dette giver øget sikkerhed. OT -personale har også adgang til at ændre eller tilføje nye maskiner, som igen automatisk opdateres af dem, der arbejder med analyse.
En DataOps løsning for fremtiden
HighByte Intelligence Hub er den første DataOps-løsning specielt udviklet til OT- og automatiseringsteam, som også gør hverdagen lettere for personale, der arbejder med analyse og optimering. Du kan læse mere om HighByte Intelligence Hub herunder, eller se HighByte’s websted her.
Vores konsulenter hjælper dig med at finde den rigtige måde at implementere en DataOps-løsning i din virksomhed.




